Generative AI (GenAI) emerges as a promising solution to bridge this critical gap, offering the potential to transform the vast quantities of organizational data into strategic insights. By harnessing the power of GenAI, organizations can unlock hidden patterns, trends, and correlations within their data, enabling them to make more informed decisions, optimize their operations, and ultimately, gain a competitive edge in the marketplace.
However, the potential of GenAI to revolutionize data-driven decision-making cannot be fully realized when the data is trapped in formats that are not directly consumable by large language models (LLMs). This can occur when valuable information is stored in PDF files or proprietary document formats like DOCX, effectively hindering the alignment of the model to the specific needs and requirements of the organization. This challenge becomes a significant roadblock, preventing organizations from fully leveraging their data assets to drive innovation and achieve their strategic objectives.
NVIDIA NIM is revolutionizing the way developers deploy AI models by providing a comprehensive suite of GPU-accelerated inference microservices. These microservices are designed to be self-hosted, offering unparalleled flexibility and control over where and how you run your AI applications. Whether you're targeting cloud environments, data centers, or even individual RTX AI PCs and workstations, NIM provides the tools and infrastructure to seamlessly integrate AI into your projects.
At its core, NIM leverages industry-standard APIs, making it incredibly easy to incorporate AI into existing applications, development frameworks, and workflows. This standardization dramatically reduces the learning curve and integration effort typically associated with deploying AI models. NIM is built on top of pre-optimized inference engines from NVIDIA and the broader AI community, including the powerful NVIDIA TensorRT and TensorRT-LLM. These engines are meticulously tuned to maximize response latency and throughput for a wide range of foundation models and NVIDIA GPUs. This means you get the best possible performance out of your hardware without having to spend countless hours on optimization.
Fedora Silverblue is a cutting-edge operating system built on the solid foundation of Fedora Linux, meticulously designed for your desktop. It's a remarkable choice for everyday computing, software development, and orchestrating container-centric workflows. Silverblue boasts an impressive array of advantages, most notably its capacity to seamlessly revert to a previous state should any unforeseen issues arise during or after system updates. This article serves as your comprehensive guide to upgrading your Fedora Silverblue system to the latest Fedora Linux 42. We'll not only walk you through the process step-by-step but also equip you with the knowledge to confidently undo the changes if anything goes awry.
Before embarking on the journey to Fedora Linux 42, it's paramount to ensure that your current system is up-to-date with all the latest patches and improvements. Open your terminal and execute the following command:
$ rpm-ostree update
Alternatively, you can leverage the graphical interface provided by GNOME Software to download and install any pending updates. Once the updates are applied, a system reboot is highly recommended to ensure that all changes are properly implemented.
The Banana Pi BPI-RV2 is here, and it's not just another single-board computer (SBC). This open-source gateway platform, born from a collaboration between Banana Pi and Siflower, is a powerhouse designed for industrial and enterprise networking. At its heart lies the Siflower SF21H8898 system-on-chip (SoC), a quad-core RISC-V processor that's ready to tackle demanding tasks in routers, access points, and control gateways.
Network latency, in the simplest terms, is the delay that occurs when data travels between your computer and a remote server. It's a crucial factor influencing the responsiveness of your online activities. High latency manifests as sluggish web browsing, lag in online games, and delays in cloud-based services. Fortunately, Linux provides a robust suite of tools to measure and monitor network latency, both in real-time and over extended periods. These tools are typically free and readily available on most Linux distributions.
In this comprehensive guide, we will explore how to leverage these tools to effectively diagnose and manage network latency issues. We'll cover:
Conducting basic latency tests using the ping command.
Tracing network paths and identifying problematic nodes with mtr.
Visualizing latency trends over time using smokeping.
Ubuntu 25.04, sporting the codename "Plucky Puffin," has officially landed. This release underscores Ubuntu's ongoing commitment to delivering a polished and user-friendly Linux experience, integrating the latest advancements in open-source technology. The development team, in close collaboration with the community and various partners, has been diligently working to introduce innovative features and address existing bugs throughout this development cycle.
Ubuntu 25.04 boasts GNOME 48 as its desktop environment, a significant upgrade that incorporates triple buffering for enhanced performance and smoother visuals. This enhancement is particularly noticeable in graphically intensive applications and desktop animations. GNOME 48 also introduces HDR settings, enabling users with compatible hardware to take full advantage of high dynamic range content, resulting in more vibrant and realistic images. A new Wellbeing Panel helps users manage their screen time and digital habits, promoting a healthier relationship with technology. Furthermore, a "Preserve Battery Health" mode optimizes battery charging patterns to extend the lifespan of laptop batteries.
Discover NX AppHub, Nitrux’s innovative system for managing and building AppImages on its Debian-based, immutable Linux distro. Learn how its CLI, daemon, and upcoming GUI simplify app management without a traditional package manager.
Nitrux, a Debian-based, systemd-free, and immutable Linux distribution, just got a major upgrade in how it handles applications. Uri Herrera, a key figure in the Nitrux Project, recently introduced NX AppHub, a fresh system designed to streamline app management and building for this unique OS. Replacing the older NX Software Center and the command-line tool zap, NX AppHub is a bold step toward a package-manager-free future. Let’s dive into what makes NX AppHub tick, how it works, and why it’s a game-changer for Nitrux users.
What is NX AppHub?
NX AppHub isn’t just one tool—it’s a suite of components working together to make app installation and management on Nitrux smoother and more flexible. Think of it as a toolbox for handling AppBoxes, which are essentially AppImages, those self-contained application bundles that run without needing a traditional package manager. This setup aligns perfectly with Nitrux’s philosophy of keeping things lightweight, independent, and user-focused.
The Manjaro Linux team has just unveiled Manjaro 25.0, codenamed Zetar, marking the newest stable release for this Arch Linux-based distro. It comes in Xfce, GNOME, and KDE Plasma flavors, offering something for every user. Let's dive into what makes this release stand out.
What is Manjaro Linux?
Manjaro Linux is a user-friendly, Arch Linux-based operating system. It’s designed to be accessible to both beginners and advanced users, providing a stable and up-to-date computing experience. Manjaro stands out due to its ease of installation, pre-configured desktop environments, and a rolling release model, ensuring you always have the latest software.
Fedora Linux 42 is the latest stable release from the Fedora Project, a community-driven initiative sponsored by Red Hat. It's designed to be a powerful, versatile, and cutting-edge distribution that showcases the newest GNU/Linux technologies. Think of it as a playground for innovation, where you can get your hands on the latest and greatest tools and features.
Why Should You Care?
Fedora is often seen as a testbed for technologies that eventually make their way into Red Hat Enterprise Linux (RHEL). This means you get to experience the future of Linux computing today. Whether you're a developer, system administrator, or just a Linux enthusiast, Fedora 42 offers something exciting.
PinePods distinguishes itself by putting you in charge of the infrastructure. Instead of relying on a third-party cloud service (like Spotify, Apple Podcasts, Pocket Casts, etc.) to store your subscriptions and listening history, PinePods runs on a server you control.
Built using Rust, a modern language known for performance and safety, PinePods is designed for robustness. It features multi-user support right out of the box, allowing separate accounts for different people using the same installation. All your data – subscriptions, episode status, user information – resides in a central database (you get to choose between MySQL/MariaDB or PostgreSQL), ensuring consistency.
Interaction primarily happens through a browser-based web interface, making your podcast library accessible from virtually any device that can connect to your server. Because it's self-hosted, your listening habits, preferences, and downloaded files stay with you, on your hardware (or chosen hosting provider), independent of any single company's ecosystem or changing privacy policies. Your podcast world follows you, not the other way around.
MX Linux 23.6 dropped recently, and it’s another solid update in the MX Linux 23 “Libretto” series. This Debian-based GNU/Linux distribution is known for being lightweight, user-friendly, and versatile, making it a go-to choice for everyone from casual users to tech enthusiasts running older hardware. Built on the Debian 12.10 “Bookworm” repositories, this release brings a fresh ISO snapshot packed with updates, including a new Linux 6.14 kernel for Advanced Hardware Support (AHS) images, UI tweaks, and a shiny new tool called UEFI Manager. Let’s dive into what makes MX Linux 23.6 worth your attention, why it’s a great pick for your next Linux adventure, and how it continues to deliver a fast, stable, and customizable experience.
If you’re aiming to break into the DevOps world but finding it tough to get hired, you might be focusing on the wrong strategies. The DevOps job market is competitive, but with the right approach, you can stand out and land that first role. This guide breaks down a tiered list of activities—ranked from low-impact to game-changing—that will maximize your chances of becoming a DevOps engineer. We’ll dive into what works, what doesn’t, and how to build a career that sets you up for long-term success. Let’s get started.
F-Tier: Low Leverage, Minimal Impact
These activities aren’t useless, but they won’t significantly boost your chances of landing a DevOps job. Think of them as the bare minimum—necessary but not enough to make you stand out.
Ever wondered what it takes to run cutting-edge AI models with billions of parameters right on your desk? I’ve been experimenting with a cluster of Mac Studios to tackle some of the largest open-source large language models (LLMs) out there, like Llama’s 405 billion parameters and DeepSeek R1’s massive 671 billion. These models are memory-hungry beasts, and while high-end GPUs like Nvidia’s H100 are the go-to for many, they’re expensive, power-hungry, and often limited in RAM. Enter Apple Silicon—specifically, Mac Studios with their unified memory architecture, power efficiency, and surprising AI potential. In this deep dive, We’ll walk you through Alex Ziskind experiments clustering Mac Studios, leveraging Apple’s MLX framework, and pushing the limits of what’s possible with consumer-grade hardware. Let’s explore how to run AI models locally, efficiently, and without breaking the bank.
Burp Suite, created by PortSwigger, is a household name for anyone in web security. It’s the go-to tool for scanning websites, intercepting traffic, and finding vulnerabilities like cross-site scripting (XSS), SQL injection, and more. With the release of Burp Suite Professional 2025.2.2.3, PortSwigger introduced Burp AI—a set of intelligent features designed to enhance your testing without taking over your job. Think of it as a super-smart assistant that automates tedious tasks, reduces false positives, and provides deeper insights into vulnerabilities.
Unlike traditional automation, Burp AI isn’t about running everything on autopilot. It’s built to work alongside you, leveraging decades of security expertise to make your penetration testing smoother and more effective. Whether you’re a seasoned ethical hacker or just dipping your toes into web security, Burp AI offers tools to level up your game. In this article, we’ll walk through a hands-on demo, explore its features, and see how it tackles real-world vulnerabilities—all from the comfort of a Kali Linux virtual machine.
Discover the top 5 cloud computing trends for 2025, from AI integration and serverless to sustainability and cloud-agnostic strategies. Learn how to stay ahead in the fast-evolving cloud landscape with practical tips and insights.
In 2025, the cloud landscape is evolving faster than ever, driven by AI breakthroughs, sustainability concerns, and new ways of building apps. Whether you’re a developer, a business owner, or just someone looking to stay ahead in tech, these trends will impact how you work and learn. Let’s dive into the top five cloud computing trends shaping the future—explained simply, with all the juicy technical details you need to know.
Trend 1: AI Is Everywhere—and It’s Running on the Cloud
Picture this: you’re scrolling through social media, and someone’s posted an anime-style selfie that looks straight out of a Studio Ghibli film. A few years ago, that would’ve taken hours in Photoshop. Now? It’s AI-generated in seconds, thanks to tools like ChatGPT or DALL-E. But here’s the thing—none of that magic happens without the cloud.
Imagine you’re a cybersecurity enthusiast, sipping coffee at your desk, ready to beef up your open-source Security Information and Event Management (SIEM) setup. You’ve heard about Sigma rules—those powerful, community-driven detection patterns that can spot threats across platforms. But integrating them into tools like Wazuh or Graylog? That’s where things get tricky. Enter Velociraptor, an open-source digital forensics and incident response tool that’s here to save the day with its slick Sigma rule integration. In this article, we’re diving deep into how to set up Sigma analysis in Velociraptor, automate scans, and pipe those juicy detections straight into Copilot for incident management. Buckle up—it’s going to be a hands-on, techy ride with a casual vibe, just like flipping through your favorite computer tutorial mag.
Why Sigma Rules Matter
Before we jump into the nitty-gritty, let’s talk about why Sigma rules are a big deal. Sigma is like the universal translator of threat detection. It’s an open-source standard for writing detection rules that work across different SIEMs and log formats. Think of it as a recipe book for spotting bad actors—whether it’s a sneaky PowerShell script or a suspicious process accessing your system. The catch? Translating Sigma rules into the native language of tools like Wazuh can be a headache. Wazuh’s rule syntax is flexible, but Sigma’s complexity often leads to a less-than-perfect match. Some folks have tried Python scripts to bridge the gap (check GitHub for repos), but the results? Meh, not robust enough.
“Which Fedora version is best for me?”—whether you’re a newbie dipping your toes into Linux or a seasoned pro looking to optimize your setup—you’ve landed in the right place. Fedora isn’t just one operating system; it’s a family of specialized editions, each tailored to different needs. In this article, we’re going to break it all down in a relaxed, easy-to-read way, keeping things simple but not shying away from the technical goodies. Buckle up, because we’re about to explore Fedora Workstation, Fedora Server, Fedora Silverblue, and more to help you find the perfect match for your computing adventures. Let’s aim for a hefty 7000 words of pure Linux love, magazine-style, so grab a coffee and let’s get started!
What Makes Fedora Special?
Before we jump into the nitty-gritty of which version reigns supreme, let’s talk about why Fedora is such a big deal in the Linux world. Born in 2003, Fedora is backed by Red Hat and a passionate global community. It’s known for being cutting-edge—think of it as the Linux distro that’s always rocking the latest tech trends, from new kernel releases to shiny desktop environments. But it’s not just about being flashy; Fedora balances innovation with stability, making it a go-to for everyone from hobbyists to enterprise IT wizards.
Pomodoro Bot V2—a sleek, voice-activated productivity sidekick that’s here to make your focus sessions smarter, hands-free, and, frankly, a whole lot cuter. If you’re new to this project, our first Pomodoro Bot was a simple yet effective tool for tracking focus sessions with a display and physical buttons. It did the job, but we knew we could level it up. And boy, did we!
This second version brings a boatload of upgrades: a fully voice-enabled system powered by a large language model (LLM), a compact audio setup, a custom-designed PCB, and an adorable new look complete with 3D-printed ears. Whether you’re a coder, a maker, or just someone who loves geeking out over tech, this guide will walk you through every step of how we built this bot, from hardware tweaks to software integration. So grab a coffee, settle in, and let’s get hands-on with this 7,000-word deep dive into the Pomodoro Bot V2!
A Quick Look Back, Pomodoro Bot V1
Before we jump into the shiny new features, let’s take a moment to appreciate where we started. Our first Pomodoro Bot was a minimalist productivity tool built around the classic Pomodoro Technique—25 minutes of focused work followed by a 5-minute break. It featured a basic display to show the timer and physical buttons for starting, stopping, and resetting sessions. Powered by a Raspberry Pi, it was functional and reliable but lacked the interactivity we craved.
While V1 got the job done, we saw room for improvement. We wanted a bot that could talk back, respond to voice commands, and look a bit more… alive. That’s where Pomodoro Bot V2 comes in, with upgrades that make it smarter, sleeker, and way more fun to use. Let’s break down what’s new!
Ghostwriter is an open-source markdown editor designed for one thing: making writing and editing Markdown files a joy. It’s not bloated with unnecessary features, and it’s not trying to be a jack-of-all-trades like some other apps (cough Notion cough). It’s laser-focused on Markdown, with a clean interface and just enough bells and whistles to keep you productive.
What makes Ghostwriter stand out? For starters, it’s cross-platform—available for Linux, Windows, and macOS. It’s lightweight, so it won’t hog your system resources, and it’s stupidly easy to install. No messing with dependencies or compiling from source (though you can if you’re feeling extra nerdy). Just download, install, and you’re off to the races.
But the real magic happens when you start using it. Ghostwriter’s interface is split into two main panels: a Markdown editor on the left and a live preview on the right. This dual-pane setup lets you write raw Markdown while instantly seeing how it’ll look when rendered. Headers, code blocks, lists—they all pop into place in real-time. If you’ve ever wrestled with Markdown syntax and wished you could see the results without switching apps, this feature alone will make you smile.
Umami, is an open-source analytics platform that’s shaking things up as a lightweight, privacy-focused alternative to Google Analytics. It’s free, self-hosted, and packed with features that make tracking and analyzing your website data feel like a breeze.
Whether you’re running a blog, an e-commerce store, or a portfolio site, Umami helps you gain insights into your visitors’ behavior with minimal fuss. In this deep dive, we’ll explore what makes Umami special, walk through setting it up, and show you how to unlock its full potential to grow your online presence—all in a relaxed, straightforward way.
Why Umami?
Google Analytics, while powerful, often bombards you with complex menus and metrics that require a PhD to decipher. Umami takes a different approach. It’s designed to give you clear, actionable insights without the bloat.
Here’s why it stands out:
Open-Source and Free: Umami’s code is publicly available, meaning you can host it yourself at no cost.
No subscriptions, no hidden fees—just pure analytics goodness.
Privacy-First: Unlike some platforms that treat user data like a gold mine, Umami respects privacy. It’s GDPR-compliant, doesn’t use cookies by default, and lets you control what data you collect.
Lightweight and Fast: Umami won’t slow down your website. Its tracking script is tiny, and the dashboard loads in a snap.
User-Friendly Interface: The clean, intuitive design makes it easy for beginners and pros alike to navigate.
Self-Hosted Flexibility: Host it on your own server or a cloud provider, giving you full control over your data.
Whether you’re a small business owner, a developer, or a marketer, Umami’s simplicity and power make it a go-to choice for understanding your audience. So, let’s roll up our sleeves and see how to get it up and running.
Getting Started with Umami: Installation Made Easy
Setting up Umami is straightforward, whether you’re a tech wizard or a newbie. You can deploy it on your own server, use a cloud provider, or leverage a platform to handle the heavy lifting. For this guide, we’ll walk through a manual self-hosted setup and touch on easier alternatives later. Don’t worry—we’ll keep it simple and avoid geek-speak overload.
Step 1: Prerequisites
Before diving in, you’ll need a few things:
A server or cloud instance (e.g., DigitalOcean, AWS, or a local machine).
Node.js (version 14 or higher) and npm installed.
A PostgreSQL or MySQL database to store your data.
A domain or IP address to access your Umami instance.
If this sounds daunting, platforms like Vercel or Render can simplify deployment with one-click options. For now, let’s assume you’re going the self-hosted route for full control.
Step 2: Downloading Umami
Umami’s code lives on GitHub, so head over to the official repository. You can clone it to your server using this command:
This creates a folder called umami with all the necessary files. Navigate into it:
cd umami
Step 3: Setting Up the Database
Umami needs a database to store your analytics data. Let’s set up PostgreSQL as an example (MySQL works similarly). If you don’t have PostgreSQL installed, grab it with:
sudo -u postgres psql
CREATE DATABASE umami;
CREATE USER umami_user WITH PASSWORD 'your_secure_password';
GRANT ALL PRIVILEGES ON DATABASE umami TO umami_user;
\q
Replace 'your_secure_password' with something strong—don’t skimp on security!
Step 4: Configuring Umami
Umami uses environment variables to connect to your database and configure settings. In the umami folder, create a .env file:
The APP_SECRET is a unique key for securing your instance—generate a random string (at least 32 characters) using a tool like openssl:
openssl rand -base64 32
Save and exit (Ctrl+O, Enter, Ctrl+X).
Step 5: Installing Dependencies and Building
With the database ready, install Umami’s dependencies:
npm install
Then, build the application:
npm run build
This prepares Umami for launch. If you hit errors (e.g., missing Node.js versions), double-check your setup or consult Umami’s documentation.
Step 6: Running Umami
Start Umami with:
npm start
If all goes well, Umami will be running on http://localhost:3000. Open your browser, navigate to your server’s IP or domain (e.g., http://your-server-ip:3000), and you’ll see the login screen. The default credentials are:
Username: admin
Password: umami
Log in, and boom—you’re in! For security, change the password immediately under Settings > Profile.
Step 7: Optional—Setting Up a Reverse Proxy
To make Umami accessible via a domain (e.g., analytics.yourwebsite.com) and secure it with HTTPS, set up a reverse proxy using Nginx or Caddy. Here’s a quick Nginx example:
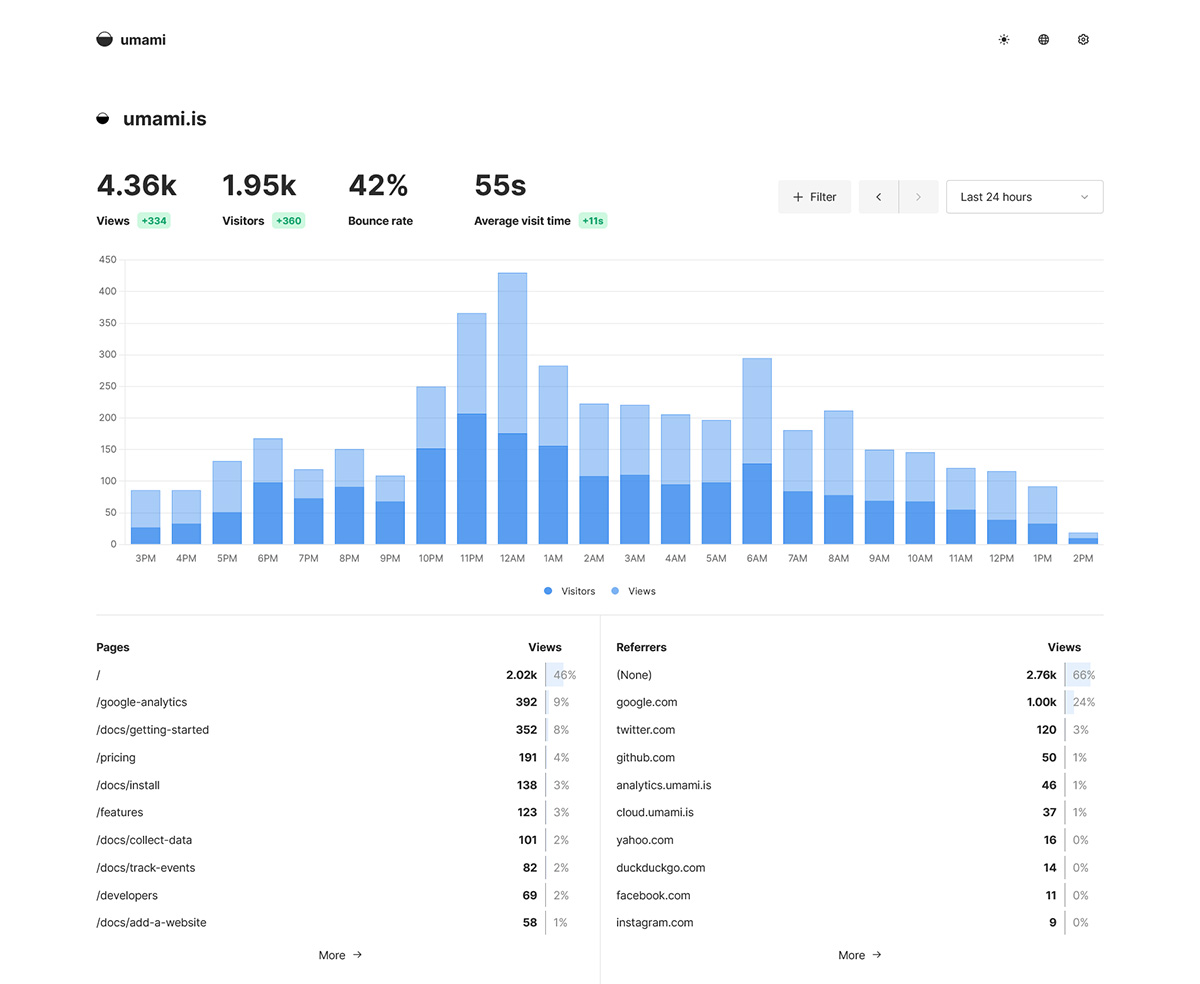
Refresh your website, visit a few pages, and head back to Umami. Click the “View” button next to your website, and you’ll see data trickling in—page views, visitors, and more. It’s alive!
Exploring the Umami Dashboard
Umami’s dashboard is where the magic happens. It’s clean, intuitive, and packed with insights. Let’s break down the key sections and what they tell you.
Overview Tab
The Overview tab is your go-to for a snapshot of your website’s performance. You’ll see:
Page Views: Total views across all pages.
Unique Visitors: Number of distinct users.
Sessions: Groups of interactions by a single user.
Bounce Rate: Percentage of visitors who leave after viewing one page.
Average Session Duration: How long users stick around.
A graph shows trends over time, with filters for:
Today: Real-time data.
Last 24 Hours: Recent activity.
This Week/Month: Broader trends.
Custom Range: Pick specific dates.
For example, if you notice a spike in page views at 8 AM, you might check which pages were hit most. Clicking into the Pages section reveals URLs like /index.html or /about, helping you spot popular content.
Events Tab
Want to know what users are doing on your site? The Events tab tracks specific actions, like button clicks or form submissions. By default, Umami logs page views, but you can add custom events. For instance, let’s track clicks on an “Add to Cart” button.
In your website’s HTML, add a data attribute to the button:
No extra JavaScript needed! If you want to include details (e.g., product ID), use:
<button data-umami-event="add-to-cart"data-umami-event-product-id="123">Add to Cart</button>
Alternatively, use JavaScript for dynamic events:
umami.track('add-to-cart', { productId: '123' });
After clicking the button a few times, check the Events tab. You’ll see “add-to-cart” listed with a count of triggers. This is gold for e-commerce sites or tracking user engagement.
Users Tab
The Users tab shows anonymous profiles of your visitors, identified by unique IDs. For each user, Umami logs:
Country: Based on IP (privacy-respecting, no precise location).
Device: Mobile, desktop, or tablet.
Operating System: Windows, macOS, iOS, etc.
Browser: Chrome, Firefox, Safari, etc.
If you run a membership site and want to tie events to specific users, use the umami.identify function:
This links actions to a user profile, perfect for SaaS platforms or forums. For public sites like blogs, the default anonymous tracking works fine.
Real-Time Tab
The Real-Time tab is like a live feed of your website’s activity. It updates instantly, showing:
Current Visitors: Who’s on your site right now.
Live Events: Page views, clicks, or custom events as they happen.
Geographic Data: A world map highlighting visitor locations.
Referrers: Where traffic is coming from (e.g., Google, Twitter).
This is great for monitoring campaigns or spotting sudden traffic spikes. For example, if a tweet goes viral, you’ll see referrers from t.co lighting up.
Compare Tab
The Compare tab lets you analyze two time periods side by side. Want to see how this week’s traffic stacks up against last week? Select “This Week” and “Previous Period.” You can filter by:
URL: Compare specific pages.
Referrer: See if Google Ads outperformed LinkedIn.
Event: Track changes in button clicks or sign-ups.
This helps you measure the impact of changes, like a new landing page or ad campaign.
Reports Tab
Reports are Umami’s secret weapon for digging deeper. You can create custom reports to track metrics like:
Insights: General trends in traffic or events.
Funnels: How users move through steps (e.g., homepage → product → checkout).
Retention: Are users returning day after day?
UTM: Track campaign performance via UTM parameters.
Revenue: Estimate earnings (if you integrate e-commerce data).
Let’s create a retention report:
Click “New Report” > “Retention.”
Name it “User Retention.”
Select your website and a date range.
Run the query.
The result shows how many users return over time. For a new site, it might show one visitor (you!), but for established sites, it reveals stickiness—crucial for subscriptions or communities.
Now, try a goal report:
Click “New Report” > “Goals.”
Name it “Daily Add to Cart.”
Set the event to add-to-cart and goal to 10 per day.
Run and save.
You’ll see progress (e.g., 2/10 add-to-carts today). Reports don’t yet integrate into the main dashboard, but checking them manually still offers powerful insights.
Advanced Features
Umami’s core is simple, but it has advanced tricks for power users. Let’s explore a few.
Teams and Permissions
Running a business with multiple stakeholders? Umami’s Teams feature lets you control access. Here’s how:
Go to Settings > Teams.
Create a team (e.g., “Marketing Crew”).
Add members via email or username.
Assign websites they can view or edit.
For example, give your SEO specialist access to traffic data but lock developers out of sensitive reports. This keeps things organized and secure.
Custom Filters
Filters supercharge your analysis. In any tab, click the filter icon to narrow down data by:
URL: Focus on a single page.
Referrer: Isolate traffic from a source.
Event: Track specific actions.
Country/Device/Browser: Segment your audience.
Say you’re running a Facebook ad. Filter by facebook.com as the referrer to see how it’s performing. Combine filters (e.g., facebook.com + /product-page) for laser-focused insights.
API Access
Developers, rejoice—Umami has a REST API for pulling data programmatically. Access it at your-umami-url/api. Common uses:
Build custom dashboards.
Integrate with Slack for real-time alerts.
Export data to spreadsheets.
To use the API, authenticate with your credentials and query endpoints like /api/websites or /api/stats. Check the API docs for details.
Dark Mode and Languages
For comfort, Umami supports dark mode (toggle it in the top-right corner) and multiple languages, including English, Spanish, and French. Pick your vibe and analyze in style.
Umami vs. Google Analytics
You might be wondering, “Why ditch Google Analytics for Umami?” Here’s a head-to-head comparison:
Ease of Use: Google Analytics’ interface can feel like a maze; Umami’s is clean and intuitive.
Privacy: Google tracks users extensively; Umami prioritizes minimal data collection.
Cost: Google Analytics is free for basic use, but premium plans are pricey. Umami’s self-hosted version is free forever.
Customization: Umami’s open-source nature lets you tweak the code; Google Analytics is a closed system.
Performance: Umami’s lightweight script won’t bog down your site; Google’s can be heavier.
That said, Google Analytics shines for massive datasets or advanced integrations (e.g., Google Ads). If you’re a small to medium-sized business, blogger, or privacy advocate, Umami’s simplicity and control are hard to beat.
Tips for Maximizing Umami
To get the most out of Umami, try these:
Track Key Events: Beyond page views, monitor actions like downloads, sign-ups, or video plays.
Set Goals: Use reports to measure progress toward business objectives.
Check Real-Time During Campaigns: Launch a sale? Watch live data to gauge impact.
Backup Your Database: Since you’re self-hosting, schedule regular backups to avoid data loss.
Explore the Docs: Umami’s documentation is a treasure trove of tips and tutorials.
Troubleshooting Common Issues
Running into hiccups? Here are quick fixes:
No Data Showing: Ensure the tracking code is correctly placed and your website’s domain matches Umami’s settings.
Database Errors: Double-check your .env file’s DATABASE_URL and confirm your database is running.
Slow Dashboard: If self-hosting on a low-spec server, upgrade your plan or optimize your database.
Login Issues: Reset the admin password via the database (see docs for steps).
For persistent problems, Umami’s GitHub issues page or community forums are great places to seek help.
Wrapping Up
At its core, analytics isn’t just about numbers—it’s about understanding your audience. Umami empowers you to answer questions like:
Which pages keep visitors hooked?
Where is my traffic coming from?
Are users taking the actions I want (e.g., buying, signing up)?
How can I improve my site’s performance?
By self-hosting Umami, you’re not just saving money—you’re taking ownership of your data in a world where privacy is increasingly rare. Plus, its open-source ethos means you’re part of a community building tools for everyone, not just big corporations.
Umami is more than an analytics tool—it’s a mindset. It proves you don’t need complex systems or deep pockets to gain deep insights into your website’s performance. With its easy setup, privacy focus, and powerful features, Umami is a game-changer for anyone looking to grow their online presence.
From tracking page views to monitoring custom events, creating reports, and comparing trends, Umami puts you in the driver’s seat. Whether you’re a solo blogger or a growing startup, it’s a tool that scales with you. So, fire up that server, paste that tracking code, and start exploring what your visitors are telling you. The data’s there—Umami just makes it fun to discover.
Picture this: you’ve got a shiny new VM downloaded, maybe it’s Kali Linux or a vulnerable machine like Metasploitable, and you’re ready to start hacking. But then you hit a snag—your VM is either wide open to your home network or completely cut off from the internet. What gives? The answer lies in how you configure your VM’s network adapters. Get it right, and your home lab is a safe playground for learning. Get it wrong, and you might accidentally let a malicious VM wreak havoc on your network.
Here’s the deal: there’s no one-size-fits-all setup. The “right” configuration depends on what you’re trying to do—whether it’s learning networking, practicing ethical hacking, or just messing around with Linux. But to make smart choices, you need to understand some networking basics. Don’t worry if you’re new to this; we’re keeping it high-level and approachable. Think of this as the “chicken and egg” of home labs—you need a lab to learn networking, but you need networking to set up a lab. Let’s break that cycle together.
Microsoft’s cooking up something fresh with Windows 11 25H2, the next big update slated for later in 2025. Early test builds are already out in the Windows Insider Dev Channel (builds 26200 and up), giving us a sneak peek at what’s coming. Based on the current Windows 11 24H2, which is still chilling in the beta channel for those who like their builds a bit more stable, 25H2 is shaping up to be… well, we’re not entirely sure yet.
Details are scarce, but whispers suggest 25H2 will play nice with Qualcomm’s upcoming Snapdragon X2 chips, which could mean snappier performance for next-gen laptops. There’s also talk of taskbar icon scaling (because who doesn’t love customizable icons?) and a quick recovery feature to save your bacon when things go sideways. Oh, and get this—Microsoft might finally ditch the infamous Blue Screen of Death for a Black Screen of Death. Gotta say, it’s a bold rebrand. Maybe they borrowed some inspo from Nvidia’s driver dramas?
Imagine this: you’re chilling on your couch, scrolling through your phone, and you stumble across a game that looks epic. No downloads, no waiting for massive files to install, no checking if your device can handle it. You just click a link, and boom—you’re playing in seconds, right in your browser, at crisp 1080p resolution and a buttery-smooth 60 frames per second. Sounds like a dream, right? Well, thanks to advancements in game streaming technology, this is the reality we’re living in today. Let’s dive into how this tech—specifically tools like Amazon GameLift Streams—is flipping the gaming industry on its head, making games more accessible, engaging, and downright fun for everyone.
The essence of Zero Trust Network Access (ZTNA) is security model that operates on the mantra of “never trust, always verify.” Unlike traditional VPNs, which might hand you the keys to an entire network once you’re inside, ZTNA is like a super-strict bouncer. It ensures you only get access to the specific apps or resources you’re authorized for, based on who you are, the device you’re using, and the context of your request.
In this guide, we’re diving into how to configure Access Server to embrace ZTNA principles. We’ll cover modern authentication, detailed access policies, network segmentation, and even some cool automation tricks with post-authentication scripts. The goal? To help you create a secure, zero-trust environment that’s both robust and user-friendly. Whether you’re an IT pro or just dipping your toes into networking, we’ll keep things clear, practical, and maybe even a little fun. Let’s get started!
What You’ll Need to Get Started
Before we jump into the nitty-gritty, let’s make sure you’ve got everything ready. Think of this as packing for a camping trip—you don’t want to realize you forgot the flashlight when you’re already in the woods. Here’s what you’ll need:
Authentication can be a headache—complex setups, heavy frameworks, or clunky interfaces that make you want to pull your hair out. But what if I told you there’s a super lightweight, easy-to-use solution that’s been making waves in the open-source world? This is Tiny Auth, a minimal authorization middleware that does exactly what it promises: keeps things simple, secure, and fast.
In this article, we’re diving deep into Tiny Auth—what it is, why it’s awesome, how it stacks up against other tools like Oralia and Authentik, and how you can set it up yourself. We’ll walk through its key features, configuration steps, and even explore some advanced use cases like OAuth integration and multi-factor authentication (MFA). Plus, we’ll touch on why this project, built by a 15-year-old developer, has skyrocketed to 1.6K GitHub stars in just a few months. Buckle up—it’s going to be a fun ride!
What Is Tiny Auth?
Tiny Auth is an open-source authentication middleware designed to sit in front of your web services and handle user logins securely. Think of it as a bouncer for your apps: it checks who’s allowed in before letting them access your services. What makes Tiny Auth stand out is its lightweight design. Unlike some beefy authentication frameworks that require tons of resources, Tiny Auth is built to be minimal, fast, and easy to deploy—perfect for homelab setups, small projects, or even larger apps where you don’t want authentication to slow things down.
At its core, Tiny Auth integrates with Traefik, a popular reverse proxy, to manage authentication for any service you put behind it. Want to secure your IT Tools dashboard, Jellyfin media server, or a custom app? Tiny Auth lets you slap a login screen in front of them with minimal fuss. It supports username/password logins, OAuth providers (like GitHub and Google), and even multi-factor authentication using TOTP (Time-based One-Time Passwords). Oh, and did I mention it’s ridiculously easy to set up with Docker Compose? Yeah, it’s that kind of project.
The project’s growth is another reason it’s worth talking about. Since January, Tiny Auth has exploded in popularity, racking up 1.6K stars on GitHub. Part of the buzz comes from its creator—a 15-year-old developer who’s somehow managed to build a tool that’s both powerful and user-friendly. That’s the kind of talent that makes you feel like you need to step up your game!
Why Choose Tiny Auth?
Before we get into the nitty-gritty of setting it up, let’s talk about why Tiny Auth might be the right choice for you. Authentication tools are a dime a dozen—Keycloak, Authentik, Oralia, you name it—so what makes Tiny Auth special? Here are a few reasons it’s turning heads:
Lightweight and Fast: Tiny Auth is designed to use minimal resources. It’s not going to hog your CPU or RAM, which is a big win for self-hosted setups on a Raspberry Pi or a small VPS.
Dead Simple Setup: If you’re familiar with Docker, you’ll be up and running in minutes. The project includes straightforward Docker Compose files, and configuration is mostly done through environment variables.
Traefik Integration: Tiny Auth plays beautifully with Traefik, a modern reverse proxy that’s already popular in the self-hosting community. It uses Traefik’s forwardAuth middleware to handle authentication, making it super flexible.
OAuth Support: Want to let users log in with GitHub, Google, or other providers? Tiny Auth has you covered with easy-to-configure OAuth integration.
Multi-Factor Authentication: Security matters, and Tiny Auth supports TOTP-based MFA, so you can add an extra layer of protection without breaking a sweat.
Active Development: The project is evolving fast, with new features and improvements being added regularly. Plus, the community is growing, which means more support and ideas.
Built by a Teen Genius: Okay, this isn’t a technical reason, but come on—a 15-year-old building something this cool? That’s inspiring and a testament to the project’s potential.
Compared to alternatives like Oralia or Authentik, Tiny Auth is less feature-heavy but makes up for it with simplicity. Oralia, for example, is great for complex setups with fine-grained access control, but it can feel overwhelming if you just need a login screen. Authentik, on the other hand, is a full-blown identity provider with tons of bells and whistles—perfect for enterprises but overkill for a homelab. Tiny Auth strikes a balance: it’s minimal enough for small projects but powerful enough to secure real-world services.
Getting Started: What You’ll Need
Ready to give Tiny Auth a spin? Before we dive into the setup, let’s make sure you’ve got everything you need. Don’t worry—it’s not a long list:
A Server or Machine: This could be a VPS, a home server, or even a Raspberry Pi. Tiny Auth is lightweight, so you don’t need a beastly machine.
Docker and Docker Compose: Tiny Auth is distributed as a Docker image, and the easiest way to deploy it is with Docker Compose.
Traefik Reverse Proxy: Since Tiny Auth relies on Traefik’s forwardAuth middleware, you’ll need Traefik set up as your reverse proxy. If you’re new to Traefik, don’t sweat it—we’ll cover the basics.
A Domain or DNS Setup: For OAuth to work smoothly (and for a polished experience), you’ll want a domain name pointing to your server. If you’re just testing locally, you can use localhost or a local DNS setup.
Basic CLI Knowledge: You’ll need to run a few commands to generate secrets and configure files, but nothing too scary.
An OAuth Provider (Optional): If you want to enable logins via GitHub, Google, or another provider, you’ll need an account with that provider to grab API credentials.
Got all that? Awesome. Let’s roll up our sleeves and get Tiny Auth running.
Step 1: Setting Up Traefik
Since Tiny Auth relies on Traefik, let’s start by making sure your Traefik setup is ready. If you already have Traefik running, feel free to skip this section. For everyone else, here’s a quick primer.
Traefik is a reverse proxy that routes incoming web traffic to your services based on rules (like domain names or paths). It’s super flexible and integrates nicely with Docker, which is why Tiny Auth uses it. To set up Traefik, you’ll need a Docker Compose file and a configuration file.
The docker.sock volume lets Traefik talk to Docker to discover services automatically.
The proxy network is where Traefik and Tiny Auth will communicate. You’ll need to create it with docker network create proxy if it doesn’t exist.
The certs volume is for SSL certificates (optional for now, but recommended for production).
Run docker-compose up -d to start Traefik, then visit http://localhost:8080 to check the Traefik dashboard. If you see it, you’re golden. Now let’s move on to Tiny Auth.
Step 2: Deploying Tiny Auth with Docker Compose
Tiny Auth’s deployment is a breeze, thanks to its Docker-based setup. The project provides a sample Docker Compose file, but we’ll walk through creating one from scratch to understand what’s going on.
Create a new directory for Tiny Auth (e.g., tiny-auth) and add a docker-compose.yml file like this:
Image: We’re pulling the official Tiny Auth image from Docker Hub.
Environment Variables: These configure Tiny Auth’s behavior (more on this later).
Volumes: We’re mounting a users.yml file to store user credentials.
Networks: Tiny Auth joins the proxy network to talk to Traefik.
Traefik Labels: These tell Traefik how to route traffic to Tiny Auth (e.g., at auth.yourdomain.com).
Before we can run this, we need to set up the environment variables and the users file.
Step 3: Configuring Environment Variables
Tiny Auth uses environment variables to customize its behavior. You can define these in a .env file or directly in your shell. Here’s what you’ll need:
SECRET: A random string used to secure cookies. Generate one with this command:
openssl rand -base64 32
Copy the output and add it to your .env file:
SECRET=your-random-secret-here
APP_URL: The URL where Tiny Auth will be accessible. For example:
APP_URL=https://auth.yourdomain.com
Replace yourdomain.com with your actual domain (or http://localhost for testing).
LOG_LEVEL: Controls how much debugging info Tiny Auth logs. 0 is verbose (great for troubleshooting), while 1 or 2 is quieter:
LOG_LEVEL=0
USERS_FILE: Points to the file where user credentials are stored:
USERS_FILE=/users.yml
OAuth Settings (optional for now): If you’re using GitHub login, you’ll need:
Create a .env file in your tiny-auth directory with these values, and Docker Compose will load them automatically.
Step 4: Creating the Users File
Tiny Auth supports two ways to manage users: inline in the environment variables or via a separate users.yml file. The file approach is cleaner and easier to manage, so that’s what we’ll use.
Create a users.yml file in your tiny-auth directory:
To generate a bcrypt hash for a password, use a tool like htpasswd or an online bcrypt generator. For example, to create a hash for the password mypassword:
htpasswd -nbBC 10 username mypassword
This will output something like:
username:$2b$10$some.long.hash.string
Copy the hash (starting with $2b$10$) and paste it into users.yml for each user. For testing, you can create users like Alice and Bob, but in a real setup, use strong passwords and unique usernames.
Step 5: Protecting a Service with Tiny Auth
Now that Tiny Auth is configured, let’s use it to secure a service. For this example, we’ll protect IT Tools, a handy web-based toolkit, but you can apply the same steps to any Dockerized service (e.g., Jellyfin, Homepage, or a custom app).
Assuming you have IT Tools running in Docker, add Tiny Auth’s middleware to its Docker Compose file. Here’s an example docker-compose.yml for IT Tools:
The traefik.http.routers.it-tools.middlewares=tinyauth label applies Tiny Auth’s middleware to this service.
The forwardauth.address points to Tiny Auth’s container (adjust if your setup differs).
The trustForwardHeader and authResponseHeaders ensure authentication works smoothly.
Run docker-compose up -d to redeploy IT Tools. Now, when you visit it-tools.yourdomain.com, you should see Tiny Auth’s login screen. Try logging in with one of your users (e.g., alice and their password). If everything’s set up right, you’ll be redirected to IT Tools after a successful login.
Step 6: Adding OAuth with GitHub
Username/password logins are great, but letting users sign in with GitHub or Google is even cooler. Tiny Auth supports OAuth providers, and setting up GitHub login is straightforward. Here’s how to do it.
Create a GitHub OAuth App
Go to your GitHub account settings and navigate to Developer settings > OAuth Apps > New OAuth App.
Fill in the details:
Application name: Something like “Tiny Auth Login”.
Homepage URL: Your Tiny Auth URL (e.g., https://auth.yourdomain.com).
Authorization callback URL: Append /callback/github to your Tiny Auth URL (e.g., https://auth.yourdomain.com/callback/github).
Click Register application.
Copy the Client ID.
Click Generate a new client secret, copy the secret, and store it securely.
The OAUTH_WHITELIST is crucial—it restricts who can log in via GitHub. For example, if you only want your GitHub account to access the service, add your GitHub email here. Without this, anyone with a GitHub account could log in, which isn’t ideal for private setups.
You’ll also need to update your users.yml to include your GitHub account. Tiny Auth maps OAuth users to local users based on their email. Add an entry like this:
Redeploy Tiny Auth with docker-compose up -d. Now, when you visit the login page, you should see a “Sign in with GitHub” button. Click it, authorize the app on GitHub, and you’ll be logged in automatically.
For extra security, Tiny Auth supports TOTP-based MFA, which lets users add a second factor (like a code from Google Authenticator or Bitwarden) to their login. Setting it up is a bit technical, but I’ll guide you through it.
Generate a TOTP Secret
Find the user you want to enable MFA for in users.yml. For example, let’s use Alice.
Run the following command to generate a TOTP secret (replace tinyauth with your container name):
docker exec tinyauth tinyauth totp generate
When prompted, enter the user’s current entry from users.yml, like:
The command will output a QR code (in ASCII) and a secret key. Scan the QR code with an authenticator app (e.g., Google Authenticator, Authy, or Bitwarden), or manually enter the secret key.
The command also outputs an updated user entry with the TOTP secret included, something like:
Copy this updated entry and replace the old one in users.yml.
Test MFA
Redeploy Tiny Auth with docker-compose up -d. Now, when you log in as Alice, you’ll be prompted for a TOTP code after entering the password. Open your authenticator app, grab the code, and enter it. If it works, you’re all set—MFA is active!
Comparing Tiny Auth to Oralia and Authentik
To give you a better sense of where Tiny Auth fits in, let’s compare it to Oralia and Authentik, two other popular authentication tools.
Tiny Auth vs. Oralia
Purpose: Oralia is designed for advanced access control, supporting complex policies like Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC). Tiny Auth focuses on simple authentication with basic authorization.
Complexity: Oralia requires more setup and configuration, especially for defining policies. Tiny Auth is plug-and-play, with minimal config needed.
Use Case: Use Oralia for enterprise-grade apps where fine-grained permissions are critical. Use Tiny Auth for homelabs or small projects where you just need a login screen.
Performance: Both are lightweight, but Tiny Auth’s minimal footprint makes it slightly leaner for basic setups.
Tiny Auth vs. Authentik
Purpose: Authentik is a full-fledged identity provider, supporting SSO, LDAP, and advanced user management. Tiny Auth is a middleware, not a complete IAM solution.
Features: Authentik has way more features (e.g., SAML, SCIM, detailed auditing), but that comes with complexity. Tiny Auth keeps it simple with username/password, OAuth, and MFA.
Ease of Use: Tiny Auth wins for quick setups—think minutes, not hours. Authentik requires more planning and resources.
Scalability: Authentik is better for large-scale deployments with thousands of users. Tiny Auth is ideal for personal or small-team use.
In short, Tiny Auth is the “keep it simple” option. If you need enterprise features, Oralia or Authentik might be better, but for most self-hosters, Tiny Auth hits the sweet spot.
Advanced Use Cases
Now that you’ve got the basics down, let’s explore some advanced ways to use Tiny Auth to level up your setup.
Securing Multiple Services
Tiny Auth’s strength is its flexibility—you can protect any service behind Traefik with a single middleware. Want to secure your entire homelab? Just add the tinyauth middleware to every service’s Docker Compose file. For example:
Jellyfin (media server): Add the middleware to stream securely.
Homepage (dashboard): Protect your app launcher.
Nextcloud (cloud storage): Keep your files private.
Each service will use the same Tiny Auth login screen, creating a unified authentication experience. You can even mix and match username/password and OAuth logins across services.
Customizing the Login Page
Tiny Auth’s default login page is functional, but what if you want to make it your own? The project is open-source, so you can fork it and tweak the frontend (built with HTML/CSS/JavaScript). For example:
Change the logo to your brand’s.
Adjust colors to match your app’s theme.
Add custom text or instructions.
To customize, clone the Tiny Auth repo, edit the frontend files, and build a new Docker image. It’s a bit of work, but it’s a great way to personalize the experience.
Using Tiny Auth in Production (with Caveats)
Tiny Auth is designed for homelab use, but with some tweaks, you could use it in production for small apps. Here are a few tips:
Enable HTTPS: Use Traefik with Let’s Encrypt to secure Tiny Auth’s traffic.
Strong Secrets: Use a robust SECRET and rotate it regularly.
Backup Users: Store users.yml in a safe place (e.g., a Git repo or encrypted storage).
Monitor Logs: Set LOG_LEVEL=1 in production to reduce noise but still catch errors.
That said, for high-stakes apps, consider a battle-tested solution like Authentik or Keycloak. Tiny Auth is awesome, but it’s still young and evolving.
Integrating with Other OAuth Providers
Beyond GitHub, Tiny Auth supports providers like Google and potentially others (check the docs for the latest). The setup is similar: grab the provider’s client ID and secret, update your .env, and add the provider’s callback URL. This flexibility makes Tiny Auth a great choice for apps where users expect modern login options.
Troubleshooting Tips
Like any tech project, things might not work perfectly the first time. Here are some common issues and fixes:
Login Fails: Double-check your users.yml for correct bcrypt hashes. Use a tool like htpasswd to verify.
OAuth Errors: Ensure your client ID, secret, and callback URL match exactly. Typos are the enemy!
Traefik Issues: Confirm both Tiny Auth and your service are on the proxy network. Check Traefik’s dashboard for routing errors.
MFA Not Prompting: Make sure the totp_secret is correctly added to users.yml and the container is redeployed.
If you’re stuck, check Tiny Auth’s logs (docker logs tinyauth) or the project’s GitHub issues page. The community is active and helpful.
Why Tiny Auth’s Growth Matters
Let’s take a moment to appreciate Tiny Auth’s meteoric rise. With 1.6K GitHub stars in just a few months, it’s clear the project is resonating with developers. Why? Because it solves a real problem—authentication doesn’t have to be complicated. In a world of bloated frameworks, Tiny Auth’s minimalist approach is refreshing.
The fact that it’s built by a 15-year-old adds an extra layer of awe. It’s a reminder that great ideas can come from anywhere, and open-source communities thrive when young talent gets involved. By using Tiny Auth, you’re not just securing your services—you’re supporting a project with huge potential.
What’s Next for Tiny Auth?
Tiny Auth is still in active development, which means things are changing fast. Based on its trajectory, here are a few features we might see in the future:
More OAuth Providers: Support for Discord, Microsoft, or other platforms could make Tiny Auth even more versatile.
Improved MFA: Options like WebAuthn or push notifications could enhance security.
Better UI Customization: A built-in way to theme the login page would be a big win.
Advanced Access Control: Basic RBAC or group-based permissions could bridge the gap with tools like Oralia.
For now, the project’s simplicity is its strength, but it’s exciting to imagine where it’ll go next. Keep an eye on the GitHub repo for updates!
Final Thoughts
Tiny Auth is one of those rare projects that makes you smile. It’s lightweight, easy to use, and packs just enough features to get the job done without overwhelming you. Whether you’re securing a homelab, building a small app, or just experimenting, Tiny Auth is a fantastic choice. Its integration with Traefik, support for OAuth, and MFA make it versatile, while its minimalist design keeps things approachable.
Setting it up is a breeze—Docker Compose, a few environment variables, and some Traefik labels, and you’re good to go. The fact that it’s built by a 15-year-old and has already hit 1.6K GitHub stars? That’s just the cherry on top.