
NVIDIA NIM is revolutionizing the way developers deploy AI models by providing a comprehensive suite of GPU-accelerated inference microservices. These microservices are designed to be self-hosted, offering unparalleled flexibility and control over where and how you run your AI applications. Whether you're targeting cloud environments, data centers, or even individual RTX AI PCs and workstations, NIM provides the tools and infrastructure to seamlessly integrate AI into your projects.
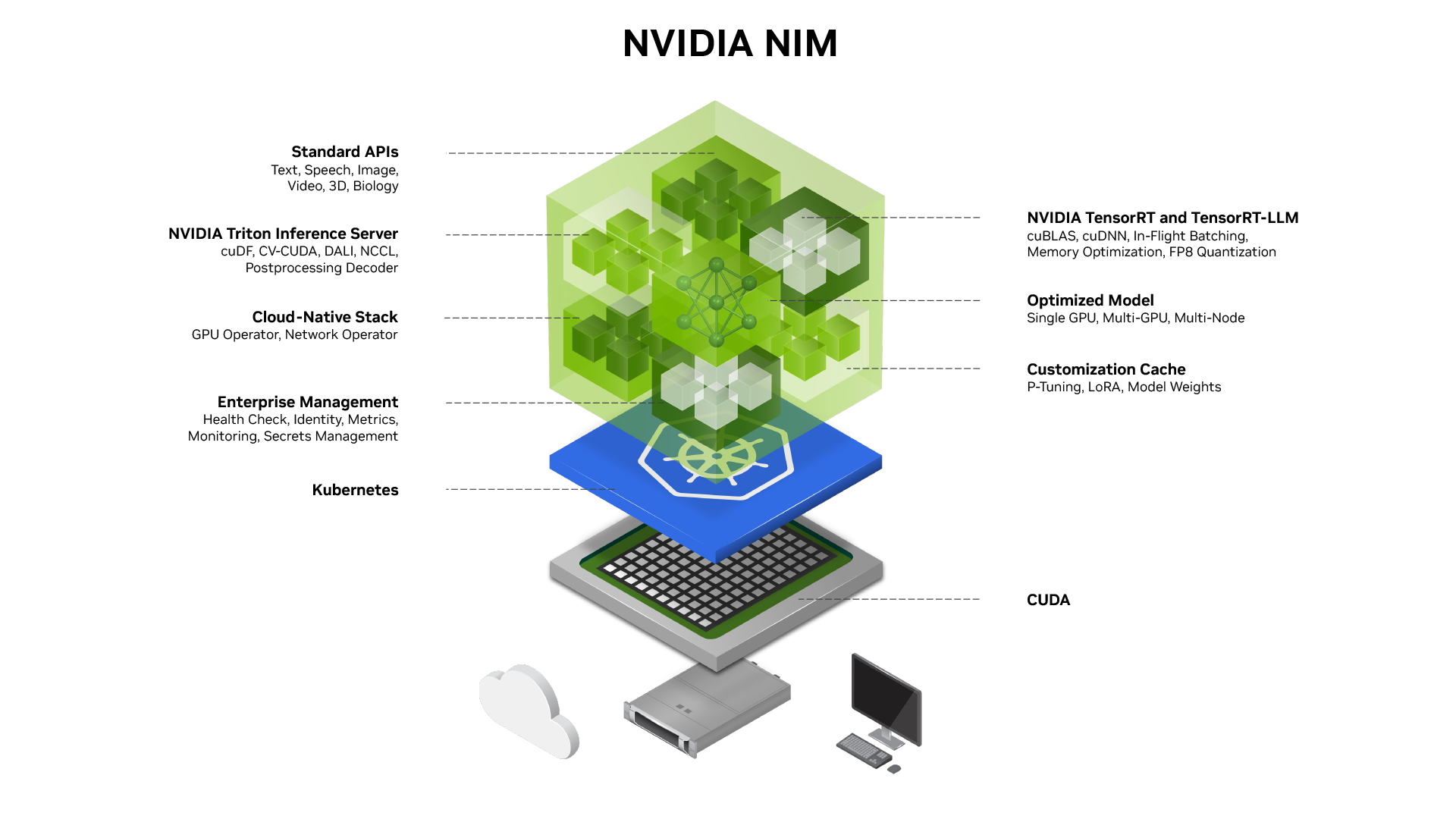
Optimized Model Performance: NIM utilizes accelerated engines like TensorRT and TensorRT-LLM, pre-built and optimized for low-latency, high-throughput inferencing on specific NVIDIA GPU systems. This ensures that your AI applications run as efficiently as possible, maximizing performance and resource utilization.Run AI Models Anywhere: NIM's prebuilt microservices can be deployed on NVIDIA GPUs in a variety of environments, including RTX AI PCs, workstations, data centers, and the cloud. This flexibility allows you to maintain security and control over your applications and data while still taking advantage of the power of NVIDIA GPUs. You can download NIM inference microservices for self-hosted deployment or use dedicated endpoints on Hugging Face to spin up instances in your preferred cloud environment.Customize AI Models: NIM allows you to fine-tune models with your own data and deploy them as NIM inference microservices. This enables you to improve accuracy for specific use cases and tailor your AI applications to meet your unique needs.Operationalization and Scale: NIM provides detailed observability metrics for dashboarding, as well as Helm charts and guides for scaling NIM on Kubernetes. This makes it easy to monitor the performance of your AI applications and scale them as needed to meet changing demands.Simplified Deployment: NIM simplifies the deployment process with pre-optimized models and industry-standard APIs. This reduces the complexity of integrating AI into existing applications and workflows, allowing developers to focus on building innovative solutions.Cost-Effectiveness: NIM's optimized inference engines and flexible deployment options help to reduce the cost of running AI applications. By maximizing performance and resource utilization, NIM enables you to get the most out of your hardware and infrastructure investments.Security and Control: NIM's self-hosting capabilities give you complete control over your applications and data. This is particularly important for organizations that need to comply with strict security and privacy regulations.Community Support: NIM is backed by a strong community of developers and AI experts. This provides access to a wealth of resources and support, making it easier to learn and use the platform.
Modularity: Each microservice is independent, making it easier to develop, test, and deploy individual components.Scalability: Microservices can be scaled independently, allowing you to allocate resources to the models that are most heavily used.Flexibility: Microservices can be deployed in a variety of environments, from cloud platforms to on-premise data centers.Reusability: Microservices can be reused across multiple applications, reducing development time and effort.
NVIDIA TensorRT: TensorRT is a high-performance inference optimizer and runtime that significantly accelerates deep learning inference. It takes a trained neural network and optimizes it for deployment on NVIDIA GPUs. TensorRT performs a variety of optimizations, including layer fusion, quantization, and kernel auto-tuning, to maximize throughput and minimize latency.TensorRT-LLM: TensorRT-LLM is specifically designed for large language models (LLMs). It provides a set of optimized kernels and techniques for running LLMs efficiently on NVIDIA GPUs. TensorRT-LLM supports a variety of LLM architectures, including Transformer, GPT, and BERT.PyTorch: PyTorch is a popular open-source machine learning framework. NIM supports PyTorch models and provides tools for optimizing them for deployment on NVIDIA GPUs.
Interoperability: Standard APIs allow NIM to be easily integrated with other systems and applications.Simplicity: Standard APIs are well-documented and easy to use, reducing the learning curve for developers.Flexibility: Standard APIs support a variety of programming languages and platforms.
Cloud Platforms: NIM supports deployment on popular cloud platforms, such as AWS, Azure, and Google Cloud. This allows you to take advantage of the scalability and cost-effectiveness of the cloud.Data Centers: NIM can be deployed on-premise in your own data center. This gives you complete control over your data and infrastructure.RTX AI PCs and Workstations: NIM can be deployed on RTX AI PCs and workstations, allowing you to run AI applications locally. This is ideal for applications that require low latency or that need to operate offline.
Chatbots and Virtual Assistants: NIM can be used to power chatbots and virtual assistants that can provide personalized support and answer customer questions.Image and Video Analysis: NIM can be used to analyze images and videos for a variety of purposes, such as object detection, facial recognition, and video surveillance.Natural Language Processing: NIM can be used for natural language processing tasks, such as text classification, sentiment analysis, and machine translation.Recommendation Systems: NIM can be used to build recommendation systems that suggest products, movies, or other items to users based on their preferences.Fraud Detection: NIM can be used to detect fraudulent transactions in real-time.Medical Image Analysis: NIM can be used to analyze medical images for disease diagnosis and treatment planning.Autonomous Vehicles: NIM can be used to power autonomous vehicles, enabling them to perceive their surroundings and make decisions.
Set Up Your Environment: Ensure you have the necessary hardware and software, including NVIDIA GPUs and drivers, as well as a compatible operating system.Install the NVIDIA NIM Toolkit: Download and install the NVIDIA NIM toolkit, which includes the necessary libraries, tools, and documentation.Choose a Pre-Trained Model: Select a pre-trained model that is suitable for your application. NVIDIA provides a variety of pre-trained models that can be used with NIM.Deploy the Model: Deploy the model as a NIM inference microservice using the NVIDIA NIM toolkit.Integrate with Your Application: Integrate the NIM inference microservice into your application using the standard APIs.Monitor and Optimize: Monitor the performance of your application and optimize it as needed.
Conclusion
NVIDIA NIM is not just a product; it's a vision for the future of AI development and deployment. As AI continues to permeate every aspect of our lives, the need for efficient, scalable, and accessible AI infrastructure will only grow. NVIDIA NIM is poised to play a central role in this future, enabling developers to create innovative AI solutions that were previously unimaginable.



0 comments:
Post a Comment